Introduction to Kafka
contents
Apache Kafka is an open-source highlighted word
A distributed system is a collection of independent computers/machines which
communicate in order to operate as a single unit. Distributed systems often
appear as a single coherent system to end users.
event streaming platform allowing for real-time stream processing.
Another paragraph with another highlighted wordThis is the explanation for the other highlighted word. that you can hover over.
can get tricky if you’ve never used it before. In part 1 of this 2 part series we’ll begin by exploring how we can ingest data from an external stage into snowflake and perform a simple ELT process. Then in part 2 we’ll learn how to integrate what we’ve done into a fully automated pipeline.Creating an external stage
text
Of course, You’ll need an s3 bucket (or the equivalent for azure/GCP) that you can access. For simplicity, we’ll be using one provided by snowflake
Another paragraph with another highlighted wordThis is the explanation for the other highlighted word. that you can hover over.
in their data engineering course called uni-kishore-pipeline, which has new data added every 5 minutes containing the login/logout events of a videogame’s player base. If you want to follow along and use the same bucket, you’ll need a snowflake account in US West Oregon.If you’d like to use your own s3 bucket, the steps are as follows: Create an IAM policy with the following permissions (you can always add more later):
- PutObject
- GetObject
- ListObject
- DeleteObject
- GetBucketLocation
- GetObjectVersion
Create an IAM user, add the policy, and then navigate to the security credentials to generate an access key. Select ‘other’ as the use case
Another paragraph with sdfsd fsd sdf sdfsd sdfs wordThis is the explanation for the other highlighted word. that you can hover over.
if you’re not overly familiar with access keys. Be sure to save your keys. Next, head over to snowflake and enter the following:You should now have access to the contents of your bucket. You can check by entering:
list @your_personal_stage;
Formatting the Data
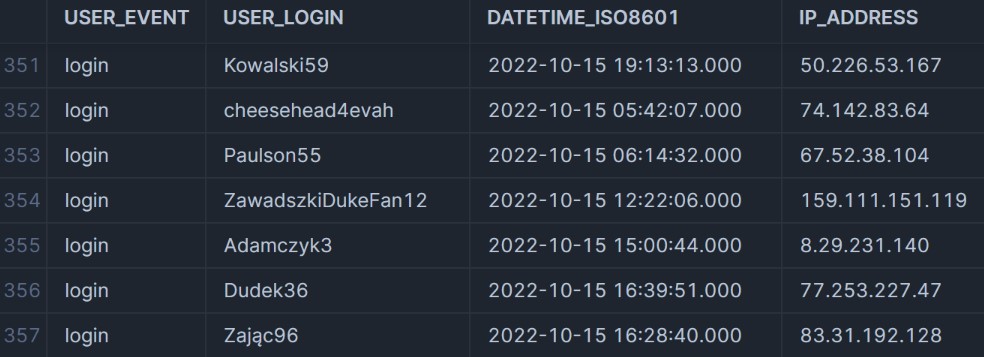
Enriching the Data
We have our data in the correct format, but we only
Another paragraph with another highlighted wordThis is the explanation for the other highlighted word. that you can hover over.
have four columns. We’re also missing information about the UTC. We do have the IP addresses, and using the snowflakeAnother paragraph with another highlighted wordThis is the explanation for the other highlighted word. that you can hover over.
marketplace, we can download the ipinfo IP geolocation database to enrich our data.The ipinfo database comes with many functions built in, and we’ll use them as
Another paragraph with another highlighted wordThis is the explanation for the other highlighted word. that you can hover over.
follows:- TO_JOIN_KEY: Converts IP addresses to specific keys that can be joined on.
- TO_INT: Converts the IP address to integers, allowing us to compare integer values rather than strings (much more efficient).
- CONVERT_TIMEZONE: Allows us to add the UTC information.
- DAYNAME: Adds the day of the week.
Taking another look at the data, we’re left with far more information to go off.
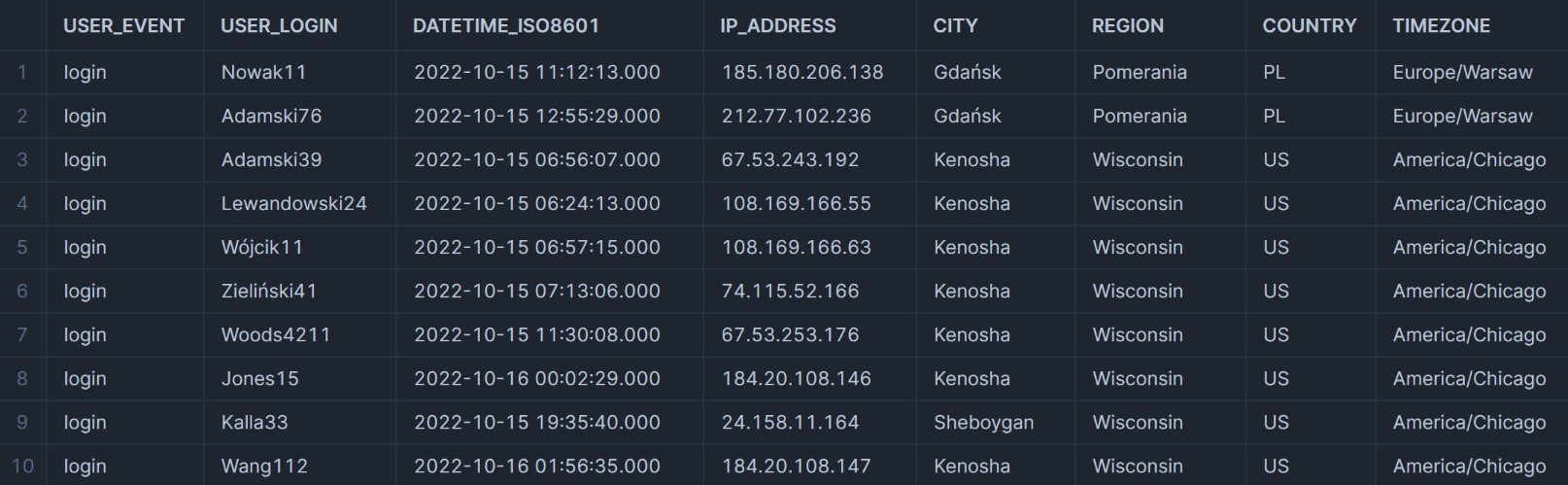
After enriching our data it’d be a good idea to save it. We’ll create a new table using CTAS called LOGS_ENHANCED.
Summary
So what have we done so far?
- Connected to our s3 bucket and created a stage
- Explored the data and created an appropriate file format
- Loaded the data into a table and created a view from the table
- Enriched our data and locked it down as a table
With that out of the way we can move on to part 2, where we’ll have some fun creating a fully automated pipeline.